正则表达解析 Markdown 语法
2019-03-07
JavaScript
阅读 2544 次
转载请注明出处
原文连接 http://blog.huanghanlian.com/article/5c80b4176f8b011040530140
文章起源
源于本博客开发实现需要
- 在首页列表需要对文字进行截取,需要截取第一张Markdown 语法的图片url。
- 在文章详情页以及关于文章展示的页面。需要对文章内容进行截取。填充
headdescription。利于seo优化
Markdown 是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式。
真实场景以及功能需求
-
文章编写
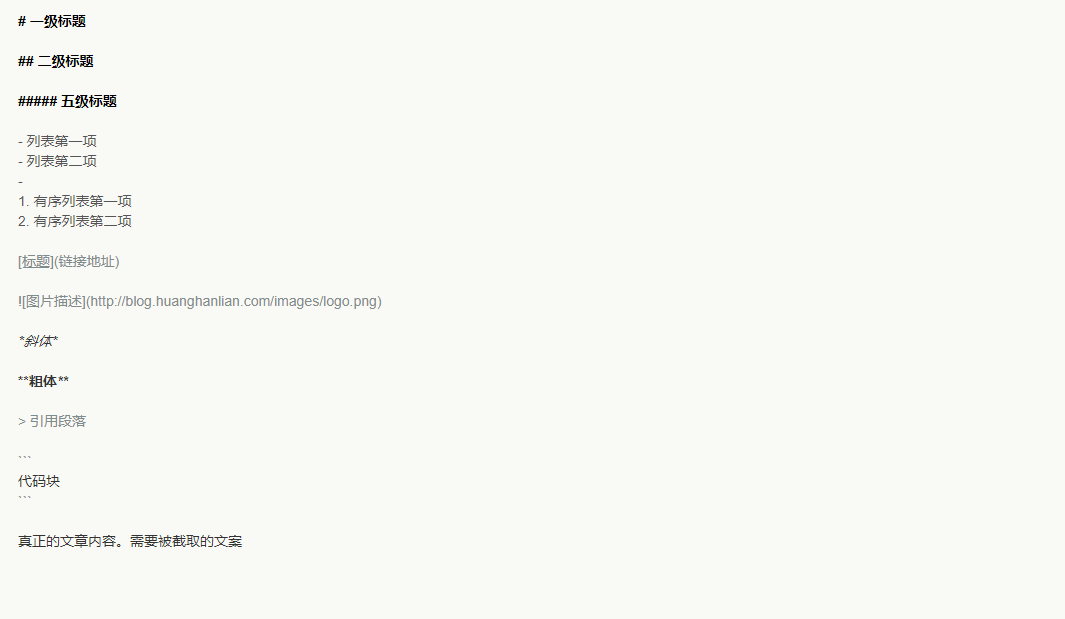
-
文章列表预览
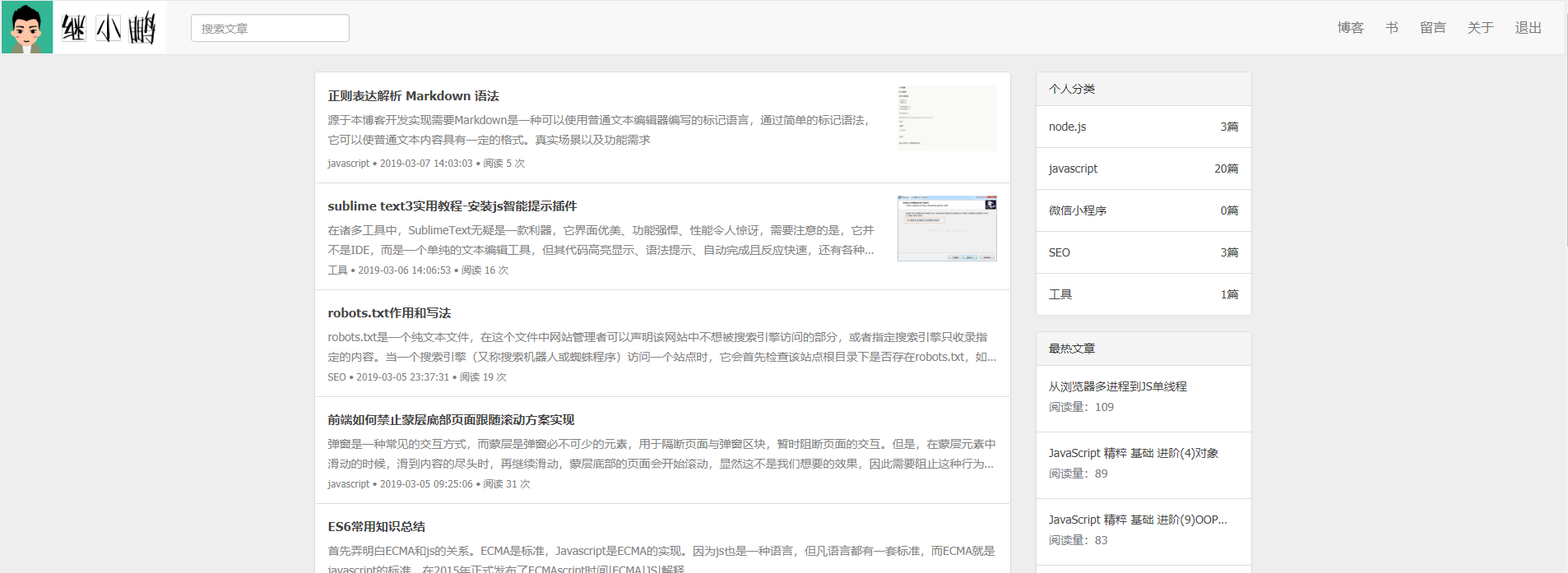
-
头部描述截取
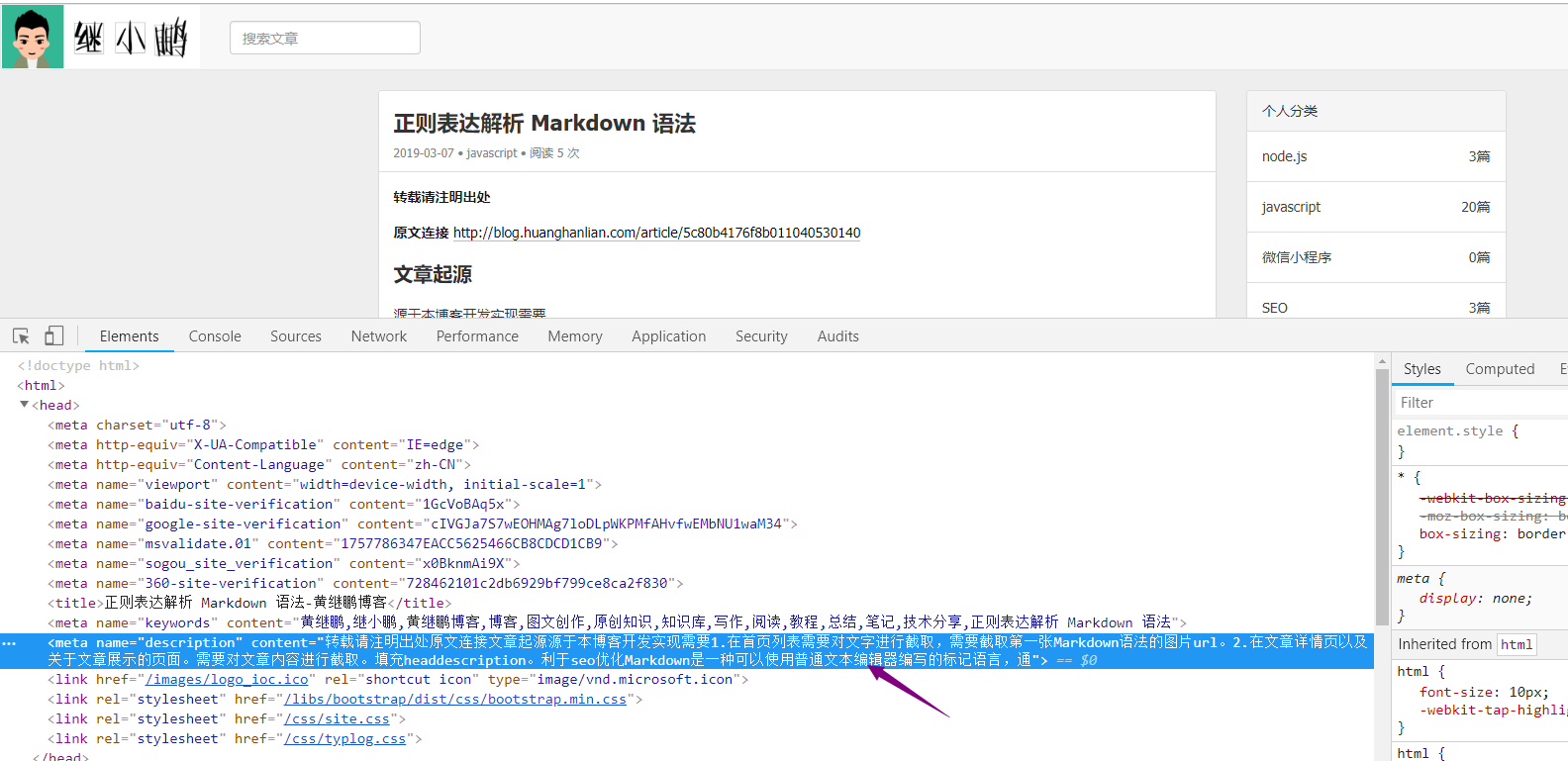
需要做的事情是将文章Markdown 语法的字符串,对特定的语句进行过滤。只显示文章正文部分
实现场景
文章编写存入数据库是字符串类型

在访问某篇文章后台会去数据库中取对应的文章数据。 然后通过匹配将Markdown 语法的字符串转义成html元素字符渲染输出
'# 一级标题\r\n## 二级标题\r\n##### 五级标题\r\n- 列表第一项\r\n- 列表第二项\r\n1. 有序列表第一项\r\n2. 有序列表第
二项\r\n[标题](链接地址)\r\n\r\n*斜体*\r\n**粗体**\r\n> 引用段落\r\n```\r\n代码块\r\n```'
现在需要做的是将这些字符去掉不想要的,提取内容部分
正则表达式规则
在使用正则表达式解析 Markdown 语法之前,我们要先对正则表达式的规则有一个基本的认识,下面我整理了一张正则表达式语法对照表。
正则表达式预定义类:
| 字符 | 含义 |
|---|---|
| . | 除了回车符和换行符之外的所有字符,等价于[^\r\n] |
| \d | 数字字符,等价于[0-9] digit |
| \D | 非数字字符,等价于[^0-9] |
| \s | 空白符,等价于[\t\n\x0B\f\r] space |
| \S | 非空白符,等价于[^\t\b\x0B\f\r] |
| \w | 单词字符(字母,数字,下划线),等价于[a-zA-Z_0-9] word |
| \W | 非单词字符,等价于[^a-zA-Z_0-9] |
边界
| 字符 | 含义 |
|---|---|
| ^ | 以xxx开始 |
| $ | 以xxx结束 |
| \b | 单词边界 |
| \B | 非单词边界 |
量词
| 字符 | 含义 |
|---|---|
| ? | 出现零次或一次(最多出现一次) |
| + | 出现一次或多次(至少出现一次) |
| * | 出现零次或多次(任意次) |
| {n} | 出现n次 |
| {n,m} | 出现n到m次 |
| {n,} | 至少出现n次 |
正则表达式解析 Markdown 语法
Markdown 语法包括标题、图片、链接、引用块、列表、粗体、斜体等,下面是解析这些语法的正则表达式和简单说明:
- 标题(表示以一个或多个“#”开头的字符串,并且“#”之后有0个或以上的字符,如:“### 三级标题”)。
^(#+)(.*)
- 链接 (在 Markdown 语法中链接的表示形式为
[链接](URL)。)。
/\[[\s\S]*?\]\([\s\S]*?\)/g
解释:
匹配 [符 开始
紧接着[\s\S]范围类 空白符或者非空白符都可以的类。
*代表出现0次或者无限次
?非贪婪模式
让正则表达式尽可能少的匹配,也就是说一旦匹配成功匹配不再继续尝试,就是非贪婪模式。
做法很简单,在量词后面加上?即可。
- 斜体(表示以一个 * 或者 _ 开头并结尾(\1表示规则和第一个集合相同),中间包含0个或多个字符的字符串)。
(\\*|_)(.*?)\\1
- 图片(部分地方同链接)
!\\[[^\\]]+\\]\\([^\\)]+\\)
- 粗体(同斜体)
(\\*\\*|__)(.*?)\\1
- 删除线(删除线)
\\~\\~(.*?)\\~\\~
- 引用块
\n(>|\\>)(.*)
- 内联代码块
`{1,2}[^`](.*?)`{1,2}
- 分割线
^-+$
- *```*包围的代码块
```([\\s\\S]*?)```[\\s]?
- 无序列表
^[\\s]*[-\\*\\+] +(.*)
- 有序列表
^[\\s]*[0-9]+\\.(.*)
function abstractFn(res){
if(!res){
return '';
}else{
var str=res.replace(/(\*\*|__)(.*?)(\*\*|__)/g,'') //全局匹配内粗体
.replace(/\!\[[\s\S]*?\]\([\s\S]*?\)/g,'') //全局匹配图片
.replace(/\[[\s\S]*?\]\([\s\S]*?\)/g,'') //全局匹配连接
.replace(/<\/?.+?\/?>/g,'') //全局匹配内html标签
.replace(/(\*)(.*?)(\*)/g,'') //全局匹配内联代码块
.replace(/`{1,2}[^`](.*?)`{1,2}/g,'') //全局匹配内联代码块
.replace(/```([\s\S]*?)```[\s]*/g,'') //全局匹配代码块
.replace(/\~\~(.*?)\~\~/g,'') //全局匹配删除线
.replace(/[\s]*[-\*\+]+(.*)/g,'') //全局匹配无序列表
.replace(/[\s]*[0-9]+\.(.*)/g,'') //全局匹配有序列表
.replace(/(#+)(.*)/g,'') //全局匹配标题
.replace(/(>+)(.*)/g,'') //全局匹配摘要
.replace(/\r\n/g,"") //全局匹配换行
.replace(/\n/g,"") //全局匹配换行
.replace(/\s/g,"") //全局匹配空字符;
return str.slice(0,155);
}
}
2条评论
-

Aresword
记得去掉冒号
回复
-
Aresword
漏了表格哈哈,我自己写的,给博主补上QwQ:(\s*(\|.*)+\|)(\n\s*(\|-)+\|)(\n\s*(\|.*)+\|)*
回复